
前回の記事でざっくり環境導入は出来たので今回はAIイラストにかかわる最新技術に触れていきます。と言っても難しい要素はなにもないです。筆者はプログラムも書けませんし、イラストも3Dもさっぱりですが気合で環境導入しています。
この界隈は
①とてつもない天才が革新的な技術を開発。論文を書く。いろいろオープンソースで公開。
②優しい天才がCUIで使えるようにする。
③親切な天才がGUI(Automatic1111 webui)で使えるようにしてくれる。
④プログラムなんもわからないけど、理想のえっちイラストを出力したいhenntaiが用途を探す。
というサイクルで回っています。論文発表から1周間くらいで最新技術が降りてくるという狂気。日進月歩という言葉がありますがまさにそんな感じです。
今回は2時間目ということでモデルの紹介、プロンプトの参考リンク集とLORA、話題のControlnetについて解説していこうと思います。
目次
モデル紹介

こちらの記事でいろいろ紹介しています。私のオススメは1時間目でも紹介した7thシリーズです。他にもリアル調のイラストが得意なabyssorangemixや実写向けモデルChilloutmixなど。それぞれ素敵なモデルがたくさんあります。正直追いきれないので


私は主にこの2つでモデルを探しています。like数順にソートすると人気モデルがわかります。
中国コミュニティや韓国コミュニティ、英語コミュニティに足を広げればもっと色々なモデルがあるので語学が得意な人は探してみてください。といってもわからないと思うのでサクッとオススメを紹介しておきます。
アニメよりのイラストが生成したい!
→7th_anime_v3_C
実写Likeなアニメイラストが生成したい!
→AbyssOrangeMix2_sfw
可愛い女の子もいいけど背景にもこだわりたい!
→Counterfeit-V2.5
とりあえずこの3つを覚えておけば問題ないです。実写系もありますが私は詳しくないのでわかりません。ChillOutmixとかいうやつが話題らしいですが、自己責任でおねがいします。
Webui周り解説
Step
20以上で破綻したら上げていく感じでいいと思います。私はいつも36で回しています。
CFG scale
7か8あたりが最近のトレンドな気がします。私はRandomizeという拡張機能で4-12の間でランダムに切り替わる用に設定し生成物のランダム性を広げています。
Sampler/Sampling method
Euler aでいいと思います。step数が少なくてもいい感じに収束するSamplerがあるみたいですがそこまで大きく変わりません。Modelとstep、Scaleを全部検証するとなると時間が足りないので私は基本Euler aで出力しています。
Batch count/Batch size
一回のGenerateで何枚作るかと何枚同時に走らせるかの設定です。Generate foreverのほうが使い勝手がいいので基本的に1でOK
Seed
ランダムにするなら-1。構図を固定して他の要素を検証するなら固定すると覚えておきましょう。
例えばSeedが12345に固定したまま、red hairというプロンプトをblue hairに書き換えると大体構図を保ったまま生成物が青髪になります。
Hires. fix
執筆予定
プロンプト参考リンク
プロンプト一覧系サイト



プロンプト付きAIイラスト投稿サイト


Loraを使ってみる
Loraってなに?
Loraは2023年3月現在において最も流行っている追加学習技術です。SDにはdreamboothやtextual inversion、hypernetworkといった学習方法があったのですが学習にハイエンドGPUが必要であったり、導入には1つあたり5GBのファイルをダウンロードする必要があったりと問題を抱えていました。
そこで登場したのがこのLow-rank Adaptation for Fast Text-to-Image Diffusion Fine-tuning通称Loraというわけです。
Loraは今までは難しかったミドルグレード帯のGPUでの学習やその使い勝手の良さから爆発的に普及、また学習用の画像のサイズを揃えなくても良くなったKohya版Loraの登場とその環境周りの充実によりプログラム何もわからない人でも簡単に追加学習が行えるようになりました。
さらにAutomatic1111 webuiに取り込まれたことによって使うだけなら超簡単に導入できるようになりました。
まずはモデルをダウンロードしよう
※ここから先はAIイラスト界隈の無法地帯です。こちらのサイトでは様々な学習済みLoraファイルが共有されていますが、それぞれのファイルのダウンロード及び利用は自己の判断において自己責任で行ってください。

ソート方法をMOST DOWNLOADED、右の期間の制限をALLTIME、最後にLORAのボタンを押すと色々探せます。アカウント作らないとR18のものは見れないのでまずはアカウントを作ってください。
使い方
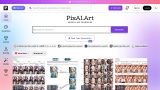
今回は私の公開している自作Lora

を導入していきます。
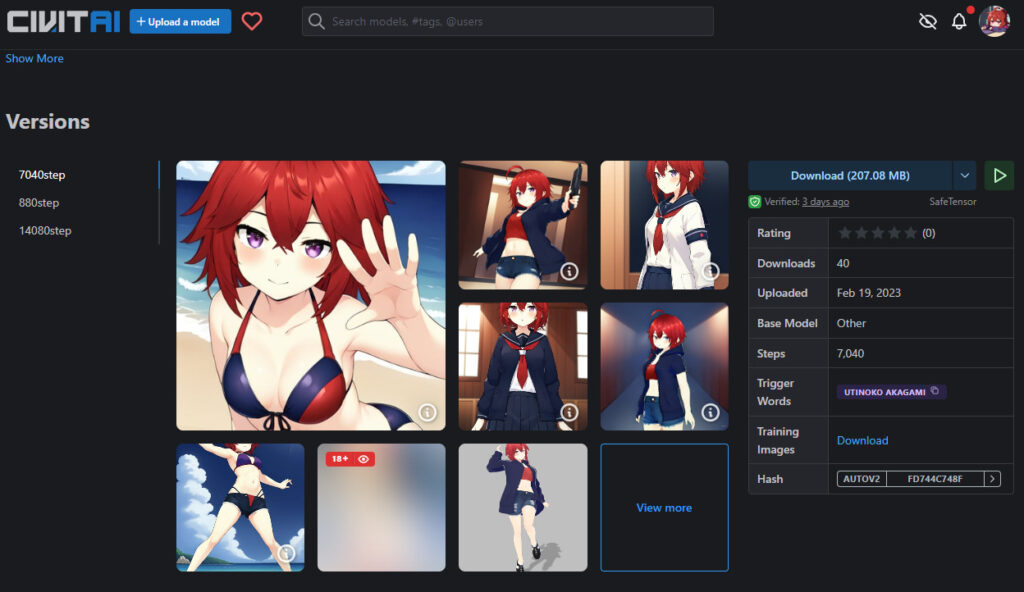
少し下のところからversionを選んでDLします。
次にDLしてきたファイルを
stable-diffusion-webui\models\Lora
webuiのフォルダ→Model→Loraと進んだフォルダに配置します。
あとはいつもどおりWebUIを開いて

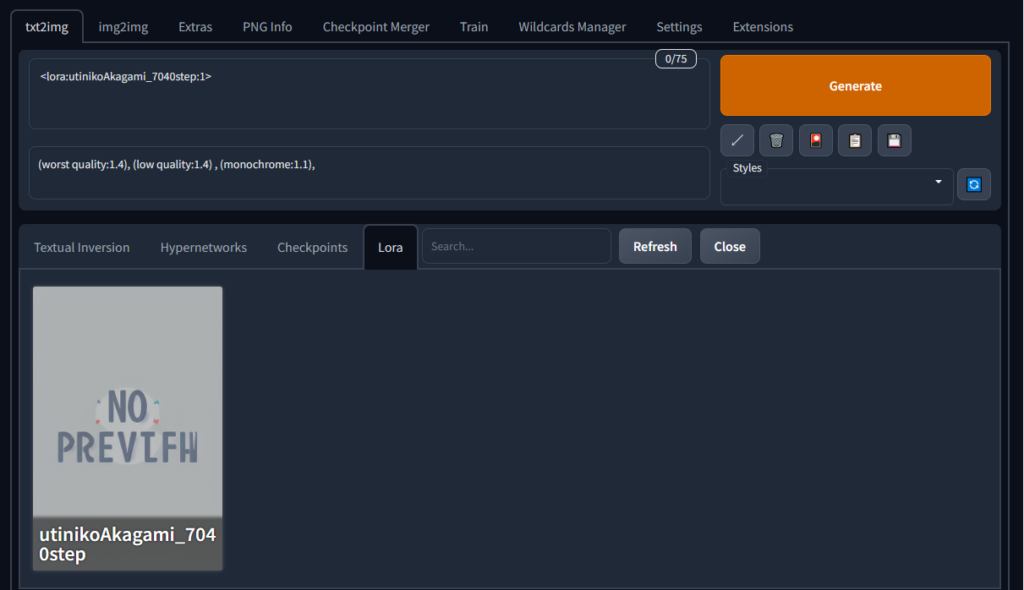
花札のマークを押してタブからLoraを選択。「No preview」という画像とともに先程配置したファイルが見つけられると思います。なければRefreshを押してください。
こちらのカードの真ん中をクリックするとプロンプトに
<lora:utinikoAkagami_7040step:1> という文字列が追加されます。この状態でGenerateを押すだけで利用できるLoraもありますが基本的には呼び出しタグを使ってこのLoraで学習した要素を呼び出します。
今回の場合 utinoko akagami というプロンプトが呼び出しタグになっているのでプロンプトに追記します。
キャラ再現Loraの場合、学習不足や過学習になっていたりすると学習元の画像が直接出力されてしまうので少し薄めて<lora:utinikoAkagami_7040step:0.6>くらいに調整。あとは再現したいキャラクターの身体的特徴や服の要素を足していきます。さらに出力したい構図や要素を追記していきます。
今回は自室でゲームをしているというシチュエーションを出力してみます。
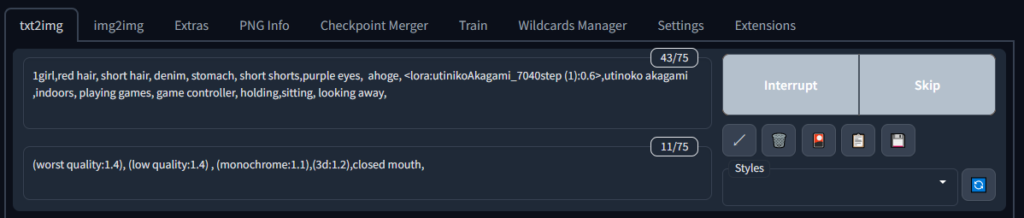
(worst quality:1.4), (low quality:1.4) , (monochrome:1.1),(3d:1.2),closed mouth,
こんな感じでプロンプトを組んでGenerate。


いい感じです。
次に制服と水着に着せ替えてみます。プロンプトを調節して…

(worst quality:1.4), (low quality:1.4) , (monochrome:1.1),(3d:1.2),closed mouth, necktie, hoodie,

(worst quality:1.4), (low quality:1.4) , (monochrome:1.1),(3d:1.2),closed mouth, necktie, hoodie, jacket, nsfw
こちらもいい感じです。
キャラ学習Loraは基本的にこのLoraタグを薄めたり強めたりしながら着せ替えや絵柄の調整を行います。構図については後述のControlNetでどうにでもなるので取り合えずは置いておきます。
Loraには他にも構図Lora、絵柄Loraなんかがあります。上のCivitaiで探せるので探してみてください。使い方は上で紹介した方法と一緒です。できの良いLora同士であればかけ合わせることも可能です。
いくつか私のお気に入りを紹介しておきます。

素のNovelAIでは難しかったぐるぐる目のLoraです。inpaintで目を修正することで既存のイラストをぐるぐる目め出来ます。
bare sholderでもいいのですがいい感じに片方だけオーバーサイズにならないのでこちらを使ってみたらいい感じになります。

ちょっと流行ったやつ。生成物をいい感じにフィギュア風にする。おそらくフィギュアの商品画像をデータセットにして1万枚以上学習しているっぽい。
応用編としてLoraの階層適用という技術もあります。階層マージと同じく構図はこのLora、絵柄はこのLora、キャラはこのLoraという風に階層別に適用するLoraを分ける技術です。この技術はまだプログラムわからん人が使える領域まで降りてきてないので私もあんまりわかりません。詳しい人は調べてみてください。
ControlNet
導入
1時間目でControlNetの拡張機能をインストールしていない人は

こちらのURLをExtensionタブの中のInstall from URLのタブに貼り付けてInstall。

次にこちらのURLからControlNetのそれぞれのモデルをDOWNLOAD


全部ダウンロードしておきます。
ダウンロードしたファイルをwebui\extensions\sd-webui-controlnet\modelsに配置。
※モデルフォルダではなくExtensionのControlNetのモデルフォルダに配置します。
導入に成功していれば
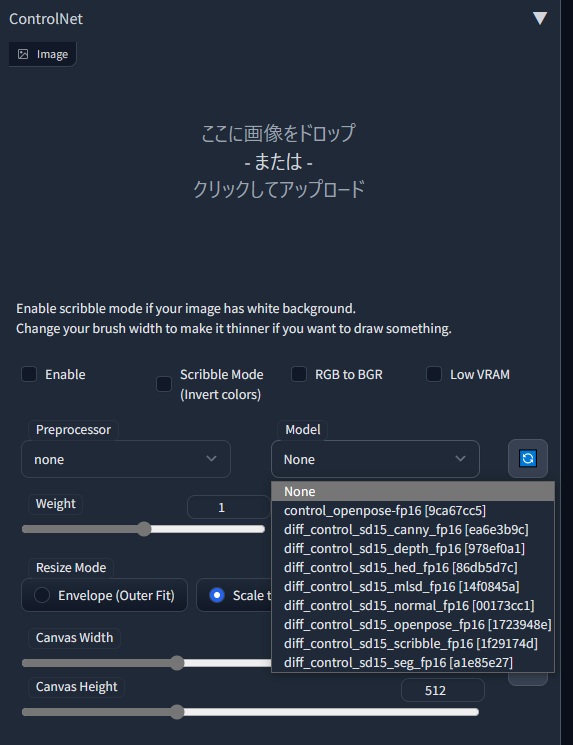
こんな感じで新しい項目がでてきます。
あとで使うのでopenpose-editorという拡張機能もいれておきます。こちらはavailableのリストからインストール出来ます。
使い方
openpose
構図を決める機能が色々あるのですが今回はTwitterなんかでも話題のopenposeを試してみます。
まずは実写でもいいので人体の構造がわかりやすい写真を用意します。今回はこちらのポーズでやってみます。

ここに画像をドロップのところに画像を配置
①Enableにチェックをいれて有効化。
②Preprocessorのところをopenposeに
③Modelの部分Preprocessorで選んだものと同じものを選択。
Generate
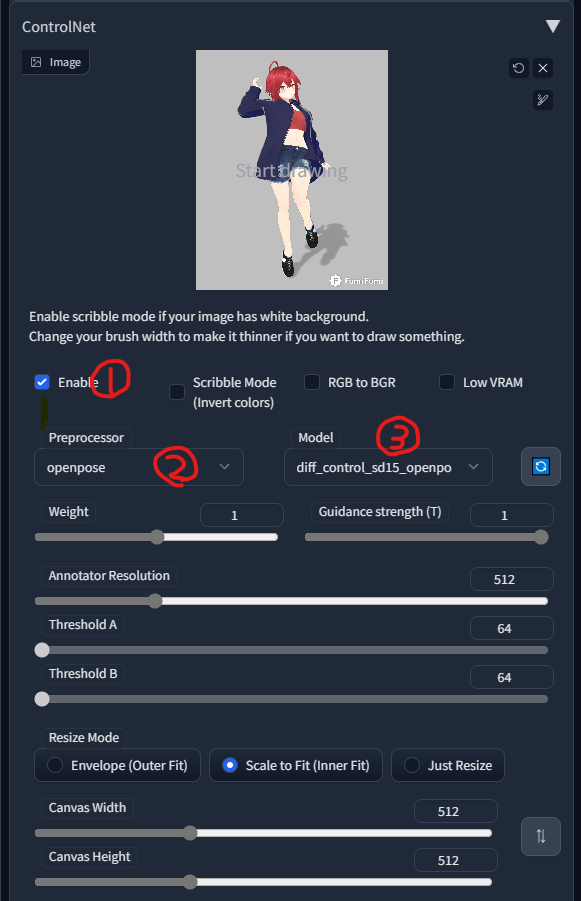
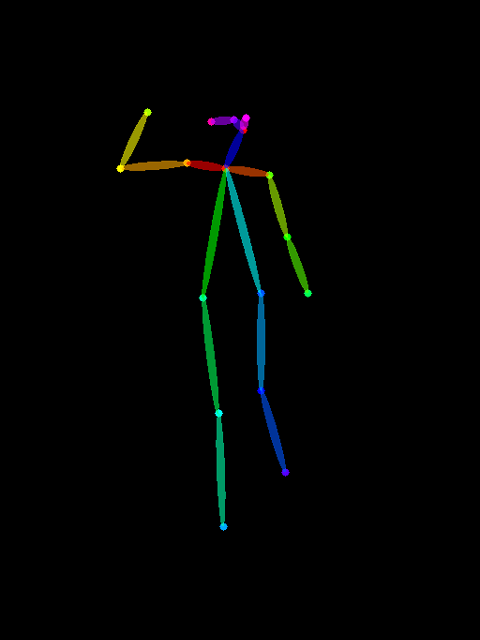

いい感じですね。
次にweightとStrengthをplotにして検証してみます。

ぶっちゃけよくわからないです。まだでて1ヶ月経ってない技術なので検証が必要です。環境導入出来た人は色々検証してみて結果をTwitterなんかで共有してください。
openpose editorも試してみます。

●の部分を動かして棒人間にposeを取らせます。棒人間の画像を最初から用意する場合はPreprocessorのところをnoneに設定します。
そして生成物がこんな感じ

構図の固定力がいまいちです。やっぱり写真や3Dモデルから棒人間を生成してから出力したほうが良さそうです。
canny
cannyも試してみます。
今回は最初から用意した。canny画像を使うのでPreprocessorのところはnoneを選択。モデルだけCannyを選んでここに画像をドロップの部分に白黒の線画をドロップ。あとはジェネレート。
ある程度構図を保ったまま出力できます。これのすごいところはi2iと違って色の情報が残らないのがいい感じ。
もちろんいらない部分を黒で塗りつぶして物だけ取り出すこともかのうです。その場合下で説明するcanny+openposeがオススメです。
canny + openpose

まずは設定からmultiControlNetを2に設定します。この設定がない場合は拡張機能をアップデートしてください。
Controlnetの欄に
モード0と1が追加されるのでそれぞれにControlnet用の画像をアップロード。
まとめ
ここまでくればAIイラストを“使う”という点においてはほぼ最前線です。次はAIイラスト界隈の沼である追加学習について解説していきます。
私の個人的な意見ですが、AIイラストがSNSなどであまり良く思われていないのは、非常に敷居が高く高度な情報の知識を持っていないと使えないものだと思われているからだと考えています。オタクにかぎらず“よくわからないものは怖い”のです。私も美容院とか怖いのでちょっとわかります。
このブログを通してAIイラストが“ちょっといいパソコン持っていれば誰でも使える技術”になれば世間のAIイラストに対する見方が少しだけ良いように向くかもしれません。私もそういう気持ちでこの記事を書いています。
で、本音は?
AIイラストをやる人が増えたらくっそ面倒な検証とか代わりにやってくれて成果だけ共有してくれるかもしれないだろ。
というわけでAIイラスト界隈の沼。追加学習編に進みます。


コメント