
最近イラストAIが登場し世間を騒がせたところですが、今度は中国からあらたに音声AIの登場です。
なにしろ約2900人の声優さんの音声データを学習させてAIを作ったんだとかこれは試さない手はない。ということで試してきたのでそのやり方とコツを解説していきます。
目次
デモサイトと音声サンプル

こちらのデモサイトで今回の音声合成AIの体験ができます。このAIの作者はゆずソフト好きすぎでしょという感じですが、ゆずソフトのゲームはキャラごとに1セリフずつ再生できる機能があるので学習元データとして非常に勝手がよかったのかなと思います。
AI製作者のCjangCjenghさんが投稿しているサンプル音声も聞いてみてください。キャラの掛け合いとかはすごく自然。やっぱりゆずソフト好きなのがとても伝わります。
例によってデモサイト激重なので上のサイトで雰囲気を確認したら、下の方法でローカル環境を作って行きましょう。
必要な環境
・Window搭載のPC
・1GBくらいの空き容量
・インターネット環境
・ちょっとだけ欠けた倫理観
一次ソースであるGitHubにはとくに必要スペックのようなものは書いていなかったのでおそらくノートPCでも行けます。イラストAIと違ってGPUをぶん回して生成するような感じではないので低スペック民でも遊べるのは嬉しいですね。
AIイラストのときもそうですが、音声の学習データが日本の著作権法にふれるかはグレーゾーンです。画像より音声のほうが著作権は厳しいはず。
今回紹介するAIはMade in Chinaで日本製ではないのでそのあたりが気になる人はブラウザバックしましょう。またやってみようという人も自己責任で行ってください。
環境構築
前回のローカル版NovelAIより簡単です。MoeGoe本体はPythonでGUIの方はC♯で動いてるみたいなのでPython環境の構築から始めます。
一次ソース
https://github.com/CjangCjengh/MoeGoe
①Pythonのインストール
前回のローカル版NovelAIでPythonを入れた人は飛ばしても大丈夫です。

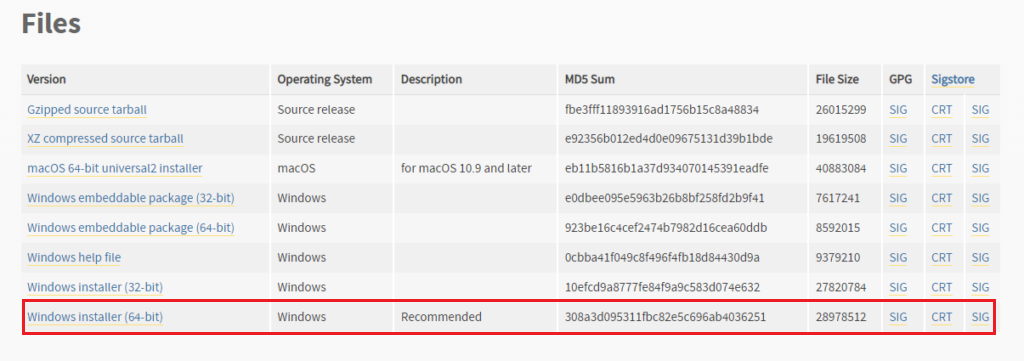
最新バージョンは何かとエラーが多いので一個古いやつを入れます。win版64bitのやつを入れてあとは流れでインストールしてください。
↑の3-1:Pythonのインストールの部分がわかりやすいのでここも参考にしてください。
②必要なデータをダウンロード
MoeGoe本体

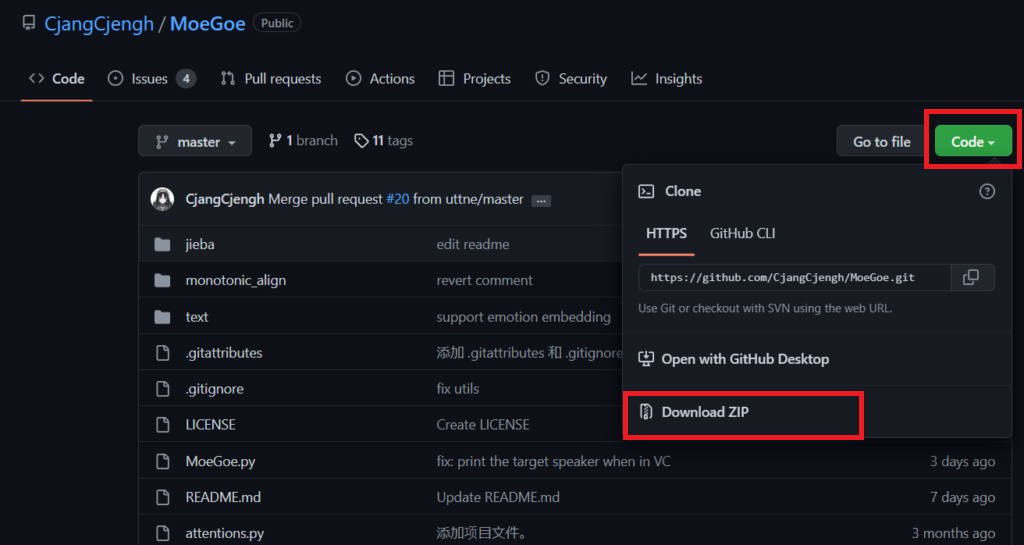
MoeGoe GUI kaiのダウンロード
5chの有志による日本語版GUI
https://uploader.cc/s/kbvq2hvfrkp1robwy00j6zose3a66ymw5z06vfupgfooggqnnzzw5ig65321mg50.zip
Modelデータのダウンロード
AI製作者による事前学習モデル
https://github.com/CjangCjengh/TTSModels
configファイルと.pthファイルの両方をダウンロードしてください。
③ファイルを一つの場所に入れる
デスクトップに適当にMoeGoeとかフォルダーを作り、そこに今までダウンロードしてきたデータを入れます。
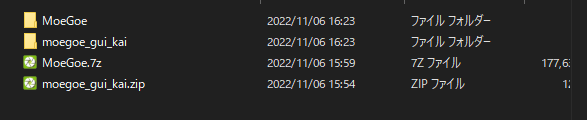
モデルデータとconfigファイルは「Desktop\moegoe\moegoe_gui_kai\MoeGoe_GUI_KAI\models」に入れておきます。
④MoeGoe GUIの起動
moegoe_gui_kai側に入っている「MoeGoe_GUI.exe」を起動します。
⑤本体・モデル・設定ファイルの読み込み
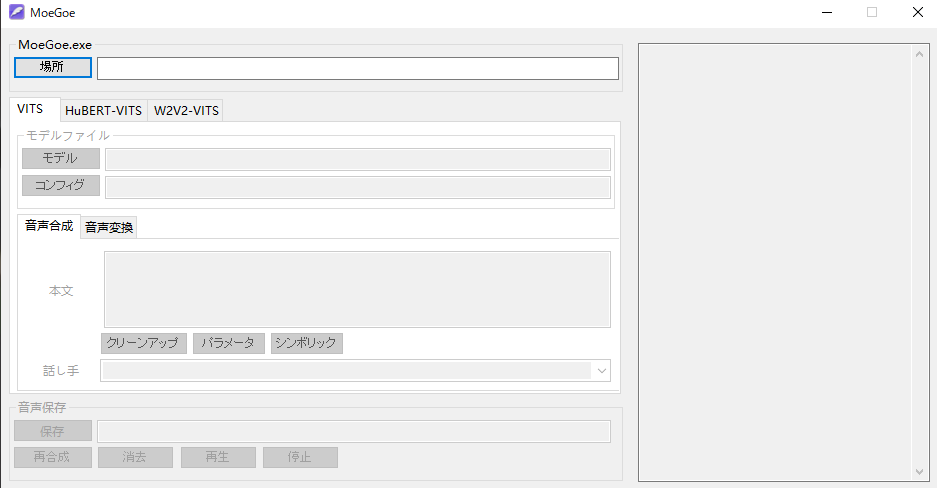
本体を起動するとこんな感じのGUIが出るので順番に場所を設定していきます。
MoeGoe.exeは本体側のC:\Users\XXX\Desktop\moegoe\MoeGoe\MoeGoe\MoeGoe.exe
モデルデータはMoeGoe_GUI_KAI側のmodelにいれた.pthファイルと.configを順番に読み込んで行きます。読み込めさえすればMoeGoeGUIフォルダに入れる必要はないです。
⑥遊ぶ
最初に音声データの出力先を設定します。デフォでは MoeGoeGUIフォルダ のoutputに設定されています。設定が完了したら再生が押せるようになります。
ここからは棒読みちゃんみたいなものなので本文に読ませたいセリフを入れて“再合成”を押し、右のCUIにSuccessが出れば完了。“再生”をおして視聴です。モデルによっては漢字やカタカナに対応していないみたいなのでローマ字入力してみるとうまくいきます。
コツと遊び方
本文下のメニューからシンボリックを選択するとアクセントを手動で組み込めるみたいです。
もう少し遊びつつ追記していきます。
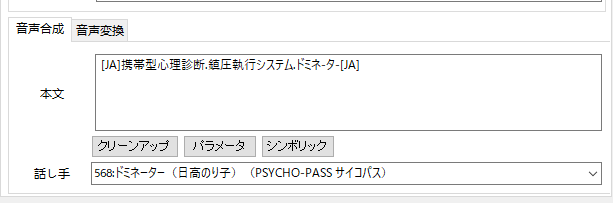
言語指定 2800名の声優が選べるモデルの遊び方。
複数言語に対応したモデル(402_epochs.pth)は最初に[JA]といれて言語指定しないといけないみたいです。英語だと[EN]中国語だと[ZH]という感じ。
喘がせてみる
ゆずソフトの学習モデルにincluded Hというのがあったのでこれはと思い検証。
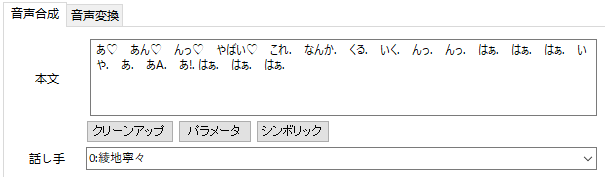
学習元が本職のプロの人だけあってかなり精度が高い。ほかの学習モデルで同じことやってもゆっくりと変わらないようなものが生成できます。
目覚まし音声を作ってみる
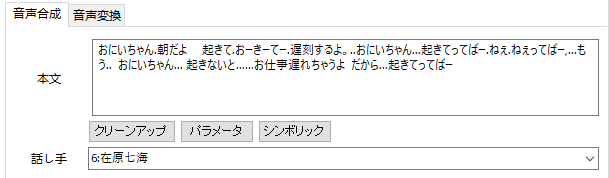
私のメインスマホにはMP3音源をアラームとして使える機能があったので、早速スマホに上の音源をうつしてアラームをセット。夢の「妹に起こしてもらう」シュチュエーションの完成です。
まとめ
まだ学習データが少ないので同人音声とまでは行きませんがもう少し研究がすすめばAIイラストによるCG、AI小説によるシナリオ、そしてAI音声合成による音声でゲーム作れそうです。
最近の1ヶ月毎にすごいAIが出てきて日本のオタク文化を侵略していく様はシンギュラリティを感じますね。数年前に流行った2045年問題を最前線で実感している感じがたまりません。新情報や新モデルが出たら追記していこうと思うのでまたアクセスしていただけると幸いです。
それでは


コメント